□ 연구데이터 정의
ㅇ 연구데이터 정의는 국가별로 약간은 상이하나, 기본적으로 연구자가 연구개발사업의 과정이나 결과로서 생산 또는 수집되는 데이터를 의미함
- 최근, 우리나라는 「국가연구개발사업의 관리 등에 관한 규정」에 연구데이터에 대한 정의를 법제화하고, 국가연구개발사업의 연구 성과물로서 관리와 활용을 위한 최소한의 근거를 제시함

| 국가 | 정의 |
| OECD | 과학 연구의 주요 출처로 사용되는 사실적 기록(수치, 문자, 이미지, 음성 등)으로 정의되며, 연구결과를 검증하는 데 필요한 데이터 |
| 영국 | 연구과정의 전 주기에서 발생하는 데이터이며, 연구자가 수집할 정보와 수집 방법, 정보 처리, 분석 계획 등을 포함 |
| 미국 | 연구데이터 관리에 관한 지침서를 통해 데이터 관리차원에서 연구의 전 주기에서 생성되는 데이터 |
| 호주 | 사실, 관찰, 이미지, 컴퓨터 프로그램 결과, 기록, 경험의 형태에서 생성되는 데이터 |
| 한국 | 연구개발과제 수행 과정에서 실시하는 각종 실험, 관찰, 조사 및 분석 등을 통하여 산출된 사실 자료로서 연구결과의 검증에 필수적인 데이터 |
□ 연구데이터 형태 및 유형
ㅇ 연구데이터의 형태는 텍스트, 숫자, 이미지, 동영상 등 다양함
ㅇ 연구데이터의 종류와 유형도 매우 다양하며 생산되는 방식에 따라 다양한 종류의 데이터가 생산되고 있음
| 연구데이터 유형 | 설명 |
| 실험 데이터 | 실험장비에서 생산되는 데이터 예) 가속기, 화학/바이오 실험데이터 |
| 관측 데이터 | 관측장비를 통해 생산되는 데이터 예) 망원경, 전자현미경, 인공위성 등 |
| 시뮬레이션 데이터 | 모델링을 통해 생산되는 데이터 예) 기후모델링, 경제전망 모델링 |
| 파생 데이터 | 원천 데이터로부터 재생산된 데이터 예) 텍스트마이닝, 3D 모델링 |
| 참조 데이터 | 평가를 거쳐 신뢰성이 공인된 데이터 예) 플라즈마 물성표준, 뇌MRI영상 참조 표준데이터 |
| 조사 데이터 | 설문조사 등을 통해 생산된 데이터 예) 시장조사, 예측조사 |
□ 연구데이터 공유의 확산
ㅇ 오픈 사이언스와 오픈 데이터라는 새로운 패러다임 속에서 데이터 공유와 출판 역시 디지털화되고 다양한 형태로 이루어지고 있음
- 21세기의 과학적 연구는 점점 데이터 집약적이고 협업적으로 바뀌어 가고 있으며(Tenopir 외, 2011) 이러한 흐름 속에서 새롭게 등장한 개념인 오픈 사이언스는 디지털 기술을 통해 연구의 전 과정을 연구 커뮤니티 내외의 모든 관련된 사람들에게 공개하려는 일련의 활동으로 정의됨(OECD, 2016; 신은정, 정원교, 2016)
- 오픈 사이언스의 영역은 오픈액세스, 오픈 데이터, 오픈 재생산가능 연구, 오픈 사이언스 평가, 오픈 사이언스 정책 그리고 오픈 사이언스 도구 등 크게 여섯 가지로 구분됨(Pontika 외, 2015)
- 그 중에서도 오픈 데이터는 연구부산물로 여겨지던 데이터의 가치를 인정하고 공개하는 개념으로 데이터의 재이용을 통해 학문 발전을 촉진할 수 있다는 점이 강조됨
ㅇ 연구 데이터의 공개를 유도하기 위해서는 데이터 공유의 필요성을 강조하는 것으로는 한계가 있고, 데이터도 학술지처럼 출판을 통해 인용도 되고 색인 DB에 등재도 될 수 있도록 할 필요성이 제기됨(Costello 2009; Smith 2009; 정영임 2017)
□ 데이터 출판 정의
ㅇ 데이터 공유 방법의 한 종류라고 할 수 있는, 데이터 출판이란 재이용과 분석을 위하여 웹을 통해 검색가능하고 고유하며 영구적인 방법으로 연구데이터, 관련 메타데이터, 관련 문서 그리고 소프트웨어 코드까지(원데이터를 가공하고 조작한 경우에는) 공개하는 것을 의미함
ㅇ 데이터 출판은 전용 리포지터리 및 데이터 학술지를 통해 이루어짐
- 리포지터리 및 데이터 학술지는 제3자나 최종사용자에 의한 향후 이용을 위해 출판의 모든 중요한 측면에서, 출판된 연구 객체를 장기간에 걸쳐 문서화, 큐레이션, 아카이빙하고 상호운용성, 인용, 품질, 검색가능성을 보장함
- 데이터 출판의 궁극적인 목적은 데이터 재생산과 재이용에 있음
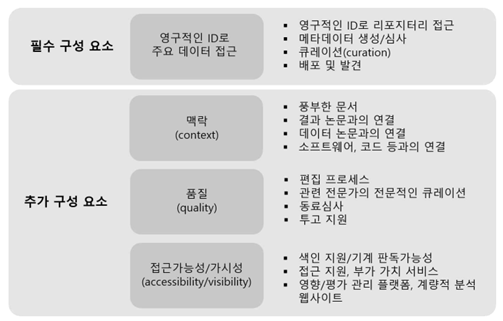
□ 데이터 출판의 구성요소
ㅇ 데이터 출판을 이루는 구성 요소에는 필수적인 구성 요소와 추가적인 구성 요소들이 있음
ㅇ (필수 구성요소) 영구적인 ID를 부여하여 데이터에 영구적인 접근을 가능하게 하는 것이 데이터 출판의 필수 요소임
- 영구적인 ID를 부여하기 위해서 데이터를 보관할 리포지터리를 선택하고 데이터의 메타데이터를 기술(description)하게 됨
- 다음으로 큐레이션 단계를 거쳐 데이터는 배포 및 발견 가능한 상태가 됨(Austin et al., 2017)
- 큐레이션(curation)이란, 데이터 인용이 적절한 형식을 따르고 있는지 그리고 원고 내의 데이터세트 기술(description)이 데이터 리포지터리 기록과 일치하는지를 확인하는 것임
ㅇ (추가 구성요소) 맥락(context), 품질(quality), 접근가능성/가시성(accessibility /visibility)이 추가적인 구성 요소임
- 맥락은 데이터 논문 혹은 기존 논문과의 연결 등을 통해 데이터에 맥락을 부여하는 것을 의미함. 데이터와 관련 메타데이터는 양방향으로 연결되어야 하며 메타데이터는 데이터의 올바른 이용 및 해석에 필수적임
- 다음으로 품질은 품질 보증(quality assurance)과 품질 관리(quality control)로 구성됨. 편집 프로세스, 전문가의 큐레이션 그리고 동료심사를 통해 품질을 보장하고 궁극적으로 데이터 재이용과 연구의 재현 가능성을 보장함
- 접근가능성 및 가시성은 색인 서비스, 연구 정보 서비스(예 : 임상연구정보서비스(CRIS)), 계량적 분석 제공 웹사이트, 데이터 출판 워크플로우(workflow)와의 연결을 제공하는 서비스를 의미함(Austin et al., 2017)
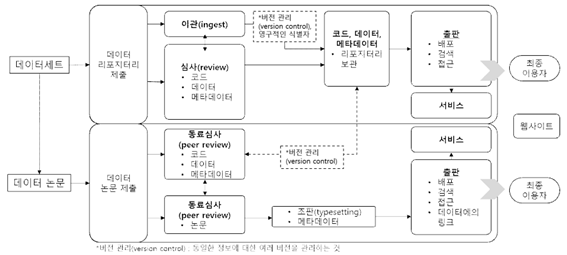
□ 데이터 출판 워크플로우
ㅇ 데이터 논문은 데이터 학술지에, 데이터셋은 데이터 리포지터리에 제출하는 두 종류의 워크플로우로 이루어짐
- 데이터 리포지터리에 제출한 데이터셋은 리포지터리에 이관되어 코드, 메타데이터 등의 심사를 거쳐 보관된 뒤 출판 및 서비스를 통해 최종 이용자 및 웹사이트에 게시됨
- 학술지에 제출한 데이터 논문은 동료심사를 거쳐 품질 보장 및 관리 후 출판 및 서비스를 통해 최종 이용자 및 웹사이트에 게시됨
'아빠방 > Article' 카테고리의 다른 글
| 주요 데이터센터 정리 (0) | 2022.12.08 |
|---|---|
| 투고심사 (Peer Review) (0) | 2022.03.28 |
| 기계학습 기반 이미지 처리 유형 (0) | 2022.02.28 |
| 블록체인 (0) | 2022.02.15 |
| 빅데이터 (0) | 2022.02.09 |




댓글